LLM Sandbox: A Locally-Hosted, Privacy-Focused Language Model Service
Language models have become essential tools for teaching and learning, academic research, and application development. However, deploying these models in the academic context presents challenges, particularly regarding privacy, intellectual property protection, and sustainable infrastructure management.
The ‘LLM Sandbox’ presented here offers one potential solution to these challenges: a locally-hosted language model service designed with UBC’s privacy requirements, technical needs, and budget constraints in mind. This service potentially enables approved people at the university to leverage language models while maintaining control over their data and avoiding vendor lock-in.
Why We Built the LLM Sandbox
The development of the LLM Sandbox was driven by several requirements that needed to be addressed simultaneously. Privacy concerns are paramount in an academic setting, and we needed to ensure that personal information of students, staff, and faculty, as well as their — and the university’s — intellectual property, would not be sent to services without Privacy Impact Assessment (PIA) approval. Additionally, data residency requirements meant that certain information potentially needed to remain within Canada.
Flexibility was another consideration; we wanted to avoid vendor lock-in that would make it difficult to adapt if costs or services changed. By supporting a common API, we aimed to reduce barriers to development and make the service more accessible.
Sustainability was equally important. We designed the LLM Sandbox with the goal of ensuring that departments or faculty support units could continue using the service after the Teaching and Learning Enhancement Fund (TLEF) funding cycle without requiring deep technical expertise.
Architecture and Technical Implementation
Core Components
We deploy Ollama on AWS EC2 instances (type: g5.xLarge) to serve language models. We selected Ollama because it provides an OpenAI-compatible API, which has become the de facto standard for LLM consumption. This compatibility allows developers who are already familiar with the OpenAI ecosystem to easily transition to our service, and, importantly, if the PIA status of OpenAI’s services change in the future (or any other provider who provides an OpenAI-API Compatible API) then applications built for the LLM Sandbox can change to use that vendor’s models without large changes to their application.
Since Ollama doesn’t natively support API keys, we incorporated LiteLLM, an open-source reverse proxy and gateway. LiteLLM adds API key management, request routing and load balancing, and usage tracking with limitations per project. This addition allows us to manage access and resources effectively across multiple users and applications.
For the hardware, we selected AWS EC2 g5.xLarge instances, which are the smallest and most cost-effective EC2 instances with attached GPUs. These instances provide a balance between performance and expense that meets our requirements for academic use.
Implementation Details
- Each g5.xlarge instance can handle 10-15 concurrent connections at approximately 10 tokens per second for small-to-medium sized models (3-10 billion parameters)
- Multiple EC2 instances are deployed to meet demand, with LiteLLM handling load balancing
- We configure Ollama with the OLLAMA_NOHISTORY flag to prevent storage of query history
Infrastructure Pricing Models
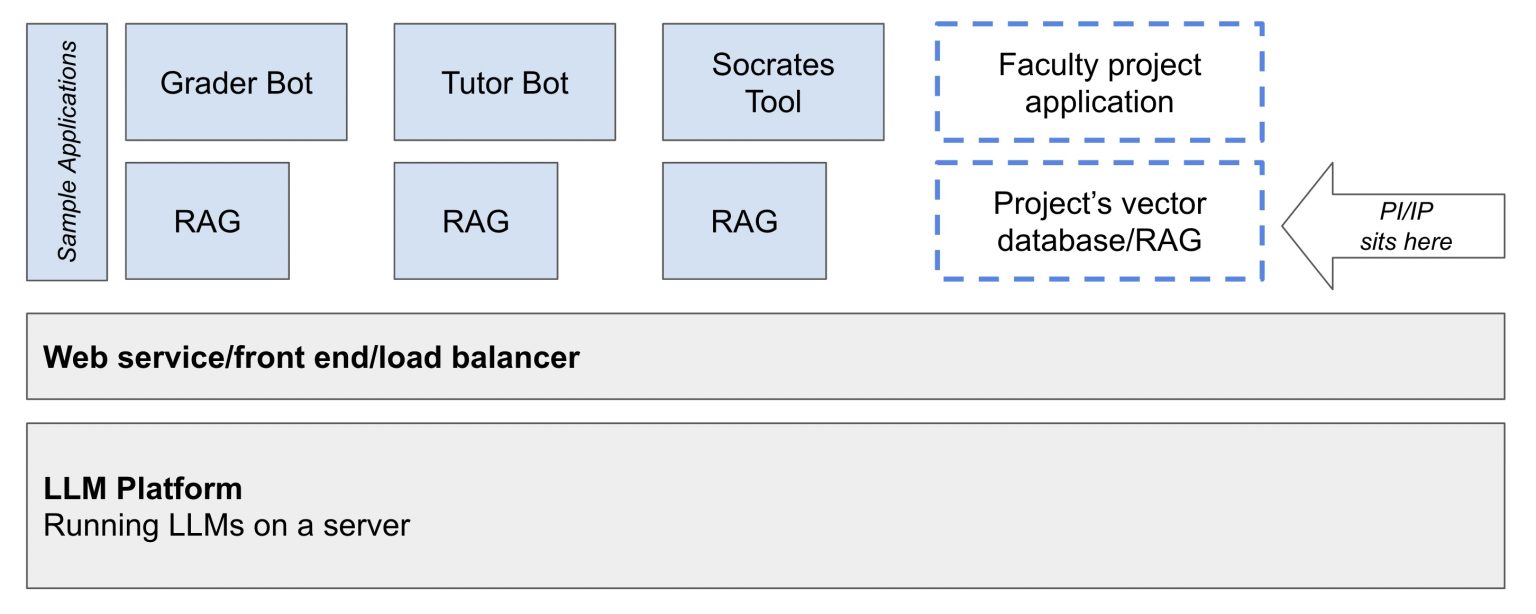
LLM Sandbox Architecture Diagram

Application Layer
GenAI applications/tools are developed in the application layer (shown as circles on the left in the image above).
User interaction: The front end – user-facing side – of all the sample applications and the applications that TLEF Applicants create (where appropriate), will provide user interaction, and can make requests directly down to the LLM layer if local/domain-specific context is not required. i.e. a RAG component is not strictly required to access the the LLM Layer.
RAG layer: Some GenAI applications require Retrieval Augmented Generation (“RAG”) to provide domain-specific context to the LLM and to improve the quality of the responses to prompts. Because RAG is specific to every implementation that requires it, RAG will not be included as a standard component of the Sandbox. Sandbox developers will develop their own RAG as part of their projects where it is required. Notably, RAG requires the storage of application-specific context information in a database file and having it developed on a per-application basis will allow faculty to control the storage and deletion of those files, which is the preferred approach to managing intellectual property in RAG contexts. Any intellectual property or personal information held in the application would likely reside within the RAG layer, and if such data is being held, then the application, and the specifics of the storage of this database, will need to be submitted for PIA approval.
Privacy and Security Considerations
An advantage of our architecture is its minimal data footprint. The LLM Sandbox infrastructure doesn’t need to store any user data, making it essentially idempotent (stateless). This design approach significantly simplifies the Privacy Impact Assessment (PIA) process for the core service.
Sensitive data handling is delegated to the individual applications that leverage the service. These applications would require a PIA process regardless of whether they use the LLM Sandbox, so this approach doesn’t create additional privacy hurdles. It also allows for specialized oversight based on each application’s specific use case, and it distributes responsibility to the teams most familiar with their data requirements and constraints.
Models and Performance
- Llama3.1 8B: Meta’s 8 billion parameter model
- Phi3 3.8B: Microsoft’s 3.8 billion parameter model
We selected these models because they fit within a single GPU’s memory on our EC2 instances while providing reasonable performance for many academic use cases.
The system achieves approximately 10 tokens per second per request, meeting our minimum performance requirement for most educational and research applications. Both models can handle contexts of varying sizes, though it’s important to note that larger contexts require more memory and may affect performance.
Cost Considerations
- GPU-equipped instances are significantly more expensive than CPU-only options, but necessary for acceptable performance
- AWS was selected due to UBC’s existing presence on the platform and our DevOps team’s familiarity with it
- The hybrid approach of reserved instances (for baseline load) and on-demand pricing (for surges) provides cost efficiency without sacrificing scalability
Alternatives
While our solution helps address the specific needs of a particular set of UBC projects, we recognize that other approaches may be more suitable in different contexts. Organizations comfortable with deeper vendor integration might find that cloud providers like AWS offer end-to-end solutions for hosting custom LLM services, which could be more cost-effective.
Similarly, if privacy and IP considerations differ from ours, services from commercial providers like OpenAI, Anthropic, or other vendors may provide more cost-effective solutions with less operational overhead.
UBC GenAI Toolkit
- Simplifies integration of generative AI capabilities into web applications
- Provides standardized interfaces for common GenAI tasks
- Shields applications from underlying implementations
- Ensures API stability even as technologies evolve
- Follows the Facade pattern, offering simplified interfaces over potentially complex underlying systems
Important Considerations
- Larger context windows require more GPU memory, which may affect performance
- Despite having fewer parameters, Phi3 3.8B has similar memory requirements to Llama3.1 8B. Always test your specific use case
- The current setup supports only text-to-text models. Image-to-text or text-to-speech capabilities would require different hardware configurations
- While changing models is technically straightforward, memory footprints must be considered to maintain performance
Getting Started
Other Useful Links
- LT Incubator Support: https://tlef.ubc.ca/uncategorized/genai-sandbox-incubator-support/
- High Level Overview of the LLM Sandbox: https://tlef.ubc.ca/uncategorized/genai-sandbox-architecture/
- Full details on the TLEF Special Call: https://tlef.ubc.ca/application/special-call/large-tlef-special-call-for-gen-ai-collaborative-cluster-grants/
Editorial Note
In writing this blog post, we used the Llama 3.1 model provided by the LLM Sandbox to help us move from a draft to a final product. We have verified the final content, including making minor edits on certain items for clarity. Here is the prompt we used:
Here is the outline of a blog post that we are writing. The audience for this is an academic setting, with folks who are at least semi-technically aware of language models. I'd like your help writing the blog post based on this outline.
The goal is to provide information about a service that we have called the LLM Sandbox. We're not 'selling' the service, we want people to know what it is, the reasons behind what we built, how we built it, and how it's being used.
```
# LLM Sandbox: A locally-hosted, privacy-focused language model service
## Constraints / Requirements
- No vendor lock-in; if cost for a service changes over night, we need to be able to switch without a complete rearchitecture effort
- Reduce barriers to go from development to production for application developers who need to leverage LLMs in their project
- No proprietary formats or APIs
- Ability to serve multiple models
- At the end of TLEF funding cycle, ensure that Departments or Faculty support units can continue to use the service without deep, detailed technical knowledge
- At least 10 tokens per second per request
- Need to be able to restrict access to the service by API Key
- To get any acceptable level of performance, Language Models require GPUs.
- Student, Staff, or Faculty Personal Information should not be sent to non-PIA approved services (PIA = Privacy Impact Assessment)
- Intellectual Property, without the IP-holders permission, should not be sent to non-PIA approved services
- PI/IP Data may have a data residency requirement (must stay in Canada)
## Architecture
Some assumtions/statements:
- Developers commonly use ollama locally
- OpenAI API is becoming the de facto standard for LLM API consumption
- Ollama provides an OpenAI-compatible API
- Ollama doesn't support API Keys natively
We install ollama (https://ollama.com/) on Amazon EC2 g5-xLarge instances (https://aws.amazon.com/ec2/instance-types/g5/) (these are the smallest/cheapest EC2 instances that have GPUs attached). We've determined that each of these instances can provide between 10 and 15 concurrent connections each at approximately 10 tokens per second for small-to-medium sized models (3-10 Billion parameters).
This means that we will need to spin up multiple of these EC2 instances to be able to serve the amount of users the TLEF projects anticipate. This means we need a load balancer to be able to serve these requests.
Combined with the fact that we also need API Key management, which enables us to set limits per TLEF project (based on their budget), we opted to use LiteLLM (https://www.litellm.ai/), an open source reverse proxy and gateway which meets our needs.
(reserved-instance pricing around CAD $7300 per year, spot pricing ~ CAD $1.40 per hour)
## Sensitive Data
This architecture means that the infrastructure that constitutes the LLM Sandbox does not need to store any data whatsoever. It is essentially idempotent. This means that the service itself is easier to get through the PIA process.
The potentially sensitive data that may be needed therefore resides in each application being built that leverages this service. This is the optimal solution as those applications would need to pass through the PIA process anyway which means that there is extra eyes, which have different areas of expertise attached to them, on these projects to ensure they're built in sustainable, secure ways.
## Models
- Llama3.1 8 Billion paramaters
- Phi3 3.8 Billion parameters
Small enough to fit within the single GPU in the EC2 instance we are using. It's fairly trivial to swap out the models for others (by installing them on ollama and then adjusting which models are available to which applications within LiteLLM) but need to pay attention to the memory footprint of the models being installed. The entire model must be able to fit into GPU memory to be able to acchieve the levels of performance quoted above.
## Cost Considerations
- GPU-attached instances are more costly than CPU-only instances
- Multiple cloud providers offer GPU-attached instances
- Our DevOps team has more experience with AWS, and UBC already has a strong presence on that platform
- 'Reserved Instance Pricing' provides a discount for long-term use of instances (minimum 12 month commitment) and is useful for a base load
- 'Spot Instance Pricing' is more expensive, but is available quickly when the service's demand increases above the capacity of the reserved instances
## Basic Architecture Diagram
[Image of diagram]
## Alternatives
- If you were comfortable with going deeper into a particular vendor's ecosystem, there are likely more cost-effective solutions available. AWS, for example, offers a full stack of services that can be used to host a custom LLM service.
- If you don't quite have the level of privacy and intellectual property considerations we have, you may be able to use a vendor (OpenAI/Anthropic etc) directly which well be more cost-effective.
## Software Toolkit
We've also developed an open source GenAI Toolkit at https://github.com/ubc/ubc-genai-toolkit-ts/
The UBC GenAI Toolkit (TypeScript-only right now) is a modular library designed to simplify the integration of Generative AI capabilities into web applications at UBC. It provides standardized interfaces for common GenAI tasks, shielding applications from underlying implementations and ensuring API stability even as technologies evolve.
This toolkit follows the Facade pattern, offering simplified interfaces over potentially complex underlying libraries or services. This allows developers of applications that consume this toolkit to focus on application logic rather than GenAI infrastructure, and enables easier adoption of new technologies or providers in the future without requiring changes to consuming applications.
## Cautionary Notes
- The context size desired by any request can impact memory footprint
- Even though Phi3 3.8B is 'less than half the size' it still has about the same memory pressure as the larger llama3.1 8b model. Ensure you're fully testing the models you use, the parameter count is not the only thing that impacts memory pressure.
- This setup is strictly for text-to-text language models. We'd like to add image-to-text or text-to-speech models in the future, but the hardware requirements for those are quite different (mostly to do with memory usage)
- Ollama has a `OLLAMA_NOHISTORY` flag which prevents the storage of the last 100 lines of text that is sent to it. Highly recommend setting this.
```
What questions do you have about this task to which the answers I provide will give you the best possible chance of success in writing the blog post?